Handling Missing Data in Pandas Data Frames –
Handling missing data is a crucial aspect of data analysis, and Pandas provides several tools and methods to deal with missing values in DataFrames. Here are some common techniques:
- Checking for Missing Data: To identify missing values in a DataFrame, you can use the
isnull()method, which returns a DataFrame of the same shape as the input with Boolean values indicating whether each element is missing.
import pandas as pd
# Create a DataFrame with missing values
df = pd.DataFrame({'A': [1, 2, None, 4], 'B': [5, None, 7, 8]})
# Check for missing values
print("Original DataFrame:")
print(df)
print("\nMissing Values Check:")
print(df.isnull())
Output:
Original DataFrame:
A B
0 1.0 5.0
1 2.0 NaN
2 NaN 7.0
3 4.0 8.0
Missing Values Check:
A B
0 False False
1 False True
2 True False
3 False False
2. Dropping Missing Values: The dropna() method allows you to remove rows or columns containing missing values.
# Drop rows with missing values
df_cleaned_rows = df.dropna()
print("\nDataFrame after dropping rows with missing values:")
print(df_cleaned_rows)
# Drop columns with missing values
df_cleaned_columns = df.dropna(axis=1)
print("\nDataFrame after dropping columns with missing values:")
print(df_cleaned_columns)
Output:
DataFrame after dropping rows with missing values:
A B
0 1.0 5.0
3 4.0 8.0
DataFrame after dropping columns with missing values:
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]
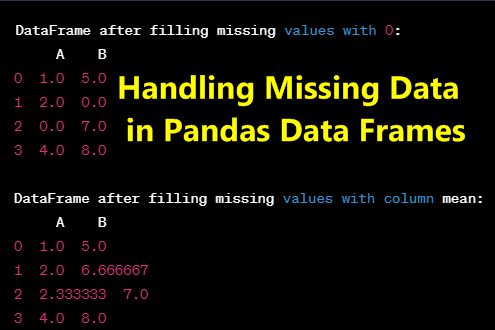
3. Filling Missing Values: The fillna() method can be used to fill missing values with a specific value or a calculated value like the mean or median.
# Fill missing values with a specific value
df_filled = df.fillna(0)
print("\nDataFrame after filling missing values with 0:")
print(df_filled)
# Fill missing values with the mean of each column
df_filled_mean = df.fillna(df.mean())
print("\nDataFrame after filling missing values with column mean:")
print(df_filled_mean)
Result:
DataFrame after filling missing values with 0:
A B
0 1.0 5.0
1 2.0 0.0
2 0.0 7.0
3 4.0 8.0
DataFrame after filling missing values with column mean:
A B
0 1.0 5.0
1 2.0 6.666667
2 2.333333 7.0
3 4.0 8.0
4. Interpolation: Pandas provides the interpolate() method, which can be used to fill missing values through linear interpolation or other methods.
# Linear interpolation along columns df_interpolated = df.interpolate()
5. Imputation: You can use statistical methods to impute missing values. For example, using the mean, median, or mode of a column to fill in missing values.
# Impute missing values with the mean of each column df_imputed = df.apply(lambda col: col.fillna(col.mean()), axis=0)
6. Replacing Values: The replace() method can be used to replace specific values in the DataFrame, including replacing missing values.
# Replace specific value with another
df_replaced = df.replace({None: 0})
Choose the appropriate method based on your specific use case and the nature of your data. The choice of method often depends on the characteristics of the dataset and the analysis you plan to perform.
![]()